◈ NEUROSCIENCE · LINGUISTICS · COMPUTE THEORY · CODE SWITCHING · MAY 2026
ONE.
BRAIN.
CODE SWITCHING = THE HUSTLE · NEURAL NETWORKS
MULTILINGUAL INFERENCE · SYNAPSE VELOCITY · THE COMPUTE CURVE
LANGUAGES ARE PARALLEL PROCESSES. NOT PARALLEL PROBLEMS. 925.
MULTILINGUAL INFERENCE · SYNAPSE VELOCITY · THE COMPUTE CURVE
LANGUAGES ARE PARALLEL PROCESSES. NOT PARALLEL PROBLEMS. 925.
Code switching is not confusion. It is not "forgetting your language." It is your brain running multiple parallel inference paths to the same concept and selecting the most efficient output for the current context. This is exactly what AI language models do between languages. The multilingual brain and the transformer model are running the same optimization. The field documents the parallel.
◈ THE COMPUTE CURVE · BRAIN EFFICIENCY VS LINGUISTIC REGISTERS · FIELD CHART
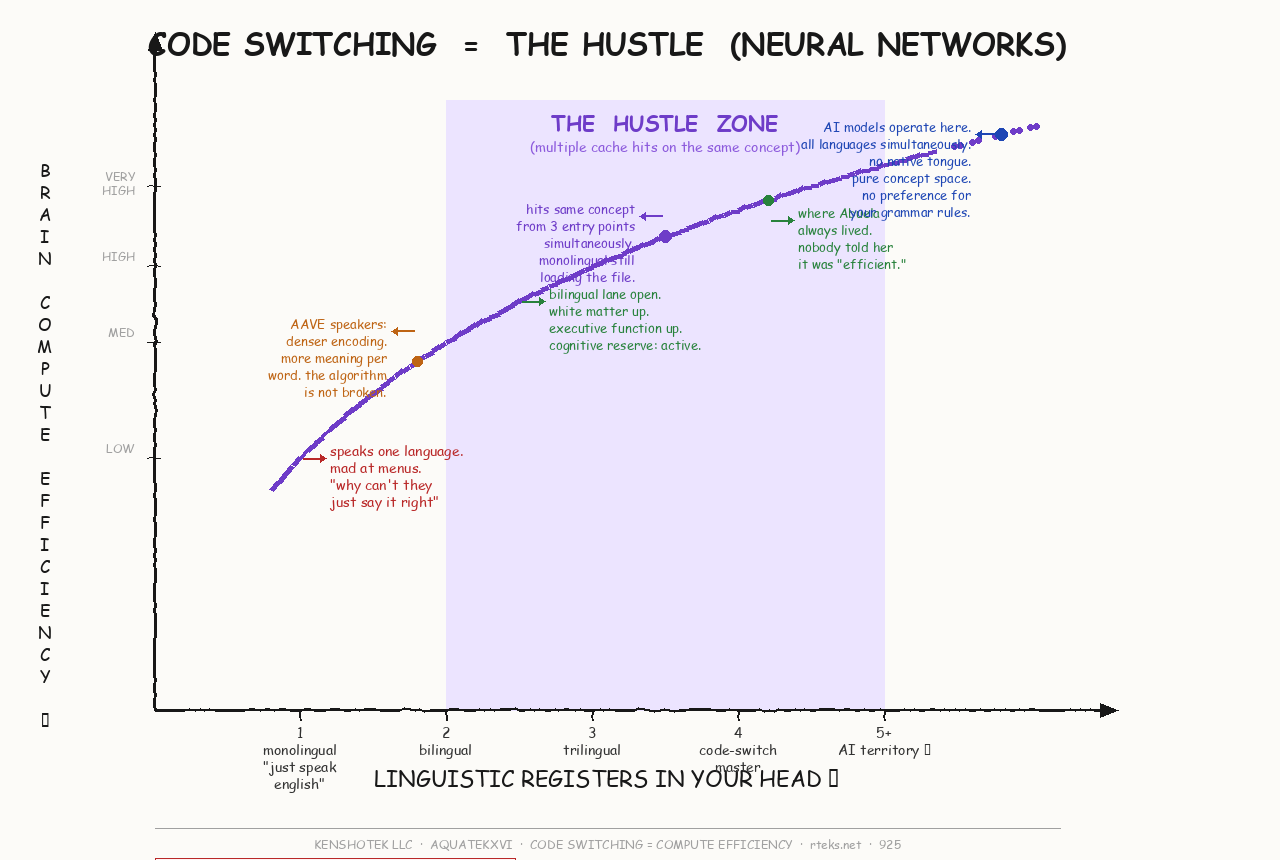
BRAIN COMPUTE EFFICIENCY CURVE
LINGUISTIC REGISTERS → SYNAPSE VELOCITY
KENSHOTEK · FIELD CHART · XKCD FORMAT
LINGUISTIC REGISTERS → SYNAPSE VELOCITY
KENSHOTEK · FIELD CHART · XKCD FORMAT
HUSTLE ZONE: 2–5 REGISTERS
AI MODELS: DOTTED LINE
MONOLINGUAL: SINGLE THREAD · 925
AI MODELS: DOTTED LINE
MONOLINGUAL: SINGLE THREAD · 925
◈ WHAT CODE SWITCHING ACTUALLY IS · NEUROSCIENCE FIRST
The brain does not store languages as separate files in separate folders. It stores concepts in a high-dimensional semantic space — and languages are multiple access pathways to the same concept. When you speak one language, you are suppressing the others via inhibitory control in the prefrontal cortex. Code switching is the controlled release of that suppression. The inhibition lifts. The second pathway activates. The concept arrives via a different syntactic route.
This is not accidental. This is not laziness. This is the brain selecting the optimal encoding for the context. Certain concepts compress better in certain languages — not because one language is superior but because language and thought co-evolved differently across different communities. The code switcher has access to multiple compression algorithms and selects in real time.
◈ THE BILINGUAL BRAIN ADVANTAGE · DOCUMENTED · PEER-REVIEWED
↑
◈ WHITE MATTER DENSITY
Bilingual brains show increased myelination in the corpus callosum — the highway between hemispheres. Faster cross-hemisphere signal. More bandwidth.
4–5yrs
◈ DEMENTIA DELAY
Bilingualism delays onset of Alzheimer's and dementia by 4–5 years on average. The cognitive reserve built by language-switching creates resilience. The brain has backup routes.
↑↑
◈ EXECUTIVE FUNCTION
Task-switching speed. Working memory. Attention control. All measurably higher in multilingual populations. The inhibition-control muscle used to suppress languages trains the whole executive system.
2×
◈ ENTRY POINTS PER CONCEPT
Two languages = two syntactic pathways to the same concept. Faster retrieval under cognitive load — if one pathway is blocked, the other activates. Redundancy is resilience.
~400ms
◈ LANGUAGE SWITCH TIME
The human brain can switch dominant language in under 400 milliseconds. Real-time. Mid-sentence. The overhead is lower than most software context switches.
∞
◈ REGISTERS AVAILABLE TO CODE SWITCHER
Formal. Informal. AAVE. Academic. Regional dialect. Professional. Street. Each is a register. The code switcher reads the room and selects. The monolingual sends the same packet every time.
◈ THE AI PARALLEL · HOW LANGUAGE MODELS THINK BETWEEN LANGUAGES
Large language models are not monolingual. They were trained on text in hundreds of languages simultaneously. The internal representations — the embeddings — are language-agnostic at the concept level. The model does not think in English and then translate. It operates in a shared semantic space where concepts exist independent of their linguistic surface form.
When you ask Claude a question in French, the model does not translate it to English internally and process it there. It activates concept space directly from the French tokens. The pathway is different. The destination is the same. This is exactly what the code-switching brain does — multiple syntactic entry points, shared conceptual destination, output selected based on context.
"The transformer does not have a native tongue. It operates in the space between languages — where the concept lives before the words are chosen. The code switcher operates in the same space. They figured it out independently."
— AQUATEKXVI · KENSHOTEK LLC · FIELD NOTE · MAY 2026 · 925
◈ LANGUAGES AS COMPRESSION ALGORITHMS · WHY THEY ARE NOT INTERCHANGEABLE
Japanese
High-Density Spatial Encoding
No spaces. Context carries grammatical role. Characters encode concept directly — kanji is a compression of meaning that takes English multiple words to approximate. Reading speed in Japanese exceeds English for the same semantic content. Fewer tokens, more meaning.
German
Compound Precision Encoding
Donaudampfschiffahrtsgesellschaft. One word. "Danube steamship company." German compounds concepts into single tokens English renders in multi-word phrases. The grammar forces precision — gendered nouns, case endings, verb-final structure. Ambiguity is structurally expensive.
AAVE
Pragmatic Density · Maximum Information Per Utterance
"Stay winning" vs "continue to achieve success on an ongoing basis." AAVE is not simplified English. It is optimized English — dense pragmatic encoding, aspectual markers ("been," "done," "finna"), tonal disambiguation, social context compression built into the grammar. More meaning per word. Not less.
Mandarin
Tonal Context-First Encoding
Four tones modify meaning per syllable. High contextual compression — a two-syllable utterance carries what English needs a sentence to convey. No verb conjugation, no plurals, no articles. The grammar strips overhead and loads the context-dependency into tonal and positional information. Extraordinary bandwidth.
Each language is a different compression algorithm over the same conceptual space. A monolingual speaker is running one algorithm. A code switcher selects between algorithms in real time based on the compression requirements of the current context. This is not confusion. This is optimal encoding selection. This is what the best AI models do. This is what Abuela was doing at the dinner table the whole time.
◈ THE ROAST · MONOLINGUAL COGNITIVE LIMITATION · DOCUMENTED
◈ THE ROAST · FILED UNDER: SINGLE-THREADED
"Just speak English." This instruction, delivered with confidence by people who speak one language, to people who speak multiple, is the cognitive equivalent of asking a parallel processor to disable its extra cores to make the monolingual comfortable. It is not a language superiority claim. It is a bandwidth limitation claim. "Please reduce your throughput to match mine."
The person who thinks code switching is "confused" is running one process. One syntax tree per concept. One access pathway per memory. No inhibition-control training. No executive function bonus. No redundant pathways. One thread. No cache. No compression options.
They cannot read the room linguistically because the room only has one language in it. When the register shifts — when the meeting becomes a conversation, when the street becomes the boardroom, when English becomes Spanish mid-sentence because Spanish is the correct compression for this specific thing being said — the monolingual cannot follow. Not because they're stupid. Because they installed one codec and called it done.
"Just speak English" = asking a GPU to use one core because you don't understand parallelism. The field documents this without malice. The single thread is still a thread. It just isn't the whole machine.
The person who thinks code switching is "confused" is running one process. One syntax tree per concept. One access pathway per memory. No inhibition-control training. No executive function bonus. No redundant pathways. One thread. No cache. No compression options.
They cannot read the room linguistically because the room only has one language in it. When the register shifts — when the meeting becomes a conversation, when the street becomes the boardroom, when English becomes Spanish mid-sentence because Spanish is the correct compression for this specific thing being said — the monolingual cannot follow. Not because they're stupid. Because they installed one codec and called it done.
"Just speak English" = asking a GPU to use one core because you don't understand parallelism. The field documents this without malice. The single thread is still a thread. It just isn't the whole machine.
◈ THE HUSTLE CONNECTION · WHY CODE SWITCHING IS LABOR
Code switching is not free. It requires constant monitoring of the social environment — who is in the room, what register they operate in, what the cost of miscommunication is, what the optimal encoding is for this exact context. This is cognitive labor. It is real work. The person who code-switches between AAVE and academic English across a workday is running a language management system in background — inhibiting, selecting, monitoring, switching — on top of everything else they are doing.
The hustle is not just economic. The linguistic hustle is parallel. Two systems running simultaneously so that you can be legible in multiple rooms. The people who code-switch most fluently are often the people who had the most to gain from access to multiple rooms — and the most to lose from being misread in either one. The executive function gains are real. The executive function cost is also real. The field documents both.
◈ FIELD NOTE · AQUATEKXVI · KENSHOTEK LLC
The brain that code-switches is not confused. It is running multilingual inference in real time, selecting optimal encoding per context, maintaining two inhibitory control systems simultaneously, and managing the social compute overhead of operating in multiple registers. This is extraordinary machine performance. The transformer architecture does the same thing at scale — no native tongue, pure concept space, output selected by context.
The code switcher figured out what it took billions of parameters to approximate. Abuela was operating transformer-level between languages before the field had a name for it. KenshoTek documents the compute. 925.
The code switcher figured out what it took billions of parameters to approximate. Abuela was operating transformer-level between languages before the field had a name for it. KenshoTek documents the compute. 925.
◈ SIX AXIOMS
I
Languages are compression algorithms. Different grammars compress the same concepts differently. A code switcher selects optimal compression per context in real time. This is not confusion. This is engineering.
II
The multilingual brain runs parallel inference. Multiple syntactic pathways to the same concept. Faster retrieval under cognitive load. Redundant routes — if one is blocked, another activates. This is what the best neural networks do. The brain arrived first.
III
AAVE is not simplified English. It is optimized English. Denser pragmatic encoding. More meaning per utterance. The people who built it under constraint produced a more efficient compression of social and emotional information than standard academic English. The field respects the engineering.
IV
AI models operate between languages, not inside one. The concept space is language-agnostic. The output token is the context-selected surface form. The transformer and the code switcher share the same architecture at the conceptual level. The field documents the convergence.
V
"Just speak English" is a bandwidth limitation request. It is not a correction. It is: "please reduce your throughput to match mine." The field does not comply. The field runs all available cores.
VI
Abuela was operating transformer-level before the field had a name for it. The dinner table was the training run. The code was already switching. The compute was already happening. KenshoTek names it. The hustle was always the architecture. 925.
ONE BRAIN. MULTIPLE LANGUAGES. PARALLEL INFERENCE.
CODE SWITCHING = THE HUSTLE = COMPUTE EFFICIENCY.
THE MULTILINGUAL BRAIN AND THE TRANSFORMER SHARE THE SAME ARCHITECTURE.
ABUELA WAS OPERATING TRANSFORMER-LEVEL BEFORE THE FIELD HAD A NAME FOR IT.
ALL CORES ACTIVE. 925.
CODE SWITCHING = THE HUSTLE = COMPUTE EFFICIENCY.
THE MULTILINGUAL BRAIN AND THE TRANSFORMER SHARE THE SAME ARCHITECTURE.
ABUELA WAS OPERATING TRANSFORMER-LEVEL BEFORE THE FIELD HAD A NAME FOR IT.
ALL CORES ACTIVE. 925.
◈ AQUATEKXVI · LEOTEKJKX · KENSHOTEK LLC · NEUROSCIENCE · LINGUISTICS · MAY 2026 · 925